EXP-38 - Uncompressed GRPO temporal drift: GSM8K ↔ Big-Math
A joint, dataset-tagged comparison of how the on-policy GRPO learning signal drifts in time on an EASY task (GSM8K) vs a HARD task (Big-Math) - to decide whether the next communication-efficient pipeline-parallel GRPO method's staleness budget and low-rank compression budget must be set per task.
Qwen2.5-1.5B-Instruct · uncompressed normal run (comm_eff OFF) · 75 global steps = 150 optimizer ticks · n=1 per task · lag axis in optimizer ticks (2/global-step ⇒ k≈5 ≙ stable 5/5 anchor, k≈20 ≙ broken 20/20 anchor). The two datasets' tensors and curves are never merged - every series is computed from its own dataset's captures and drawn as a separate, dataset-labelled line.
TL;DR - is the budget task-dependent?
- Gradient-anchor staleness budget - YES - task-dependent. Easy task keeps a short usable window (cos 0.51→0.18 over k=1→5); the hard task is decorrelated even at lag 1 (cos 0.018). On a hard task a stale uncompressed gradient is junk at any latency.
- Uncompressed-gradient effective rank - YES - task-dependent: 50 (easy) vs 78 (hard, ≈ the low-rank compression budget r=77).
- Backward boundary traffic (grad_h) rank - YES - task-dependent: 105 (easy) vs 180 (hard). The backward link gets harder to compress as the task gets harder.
- Forward activation low-rank-ness - no - invariant: the forward boundary activation h is strongly low-rank (rank ≈1 — one massive-activation direction holds ~99% of the energy) on BOTH tasks. The activation-compression primitive (rank-r forward compression) is task-independent; its budget (and the gradient/backward budgets) are not.
How the rank numbers were computed: each captured 2D tensor was decomposed with SVD, then we counted the fewest singular directions needed to explain 90% of squared singular-value energy. Reported ranks are medians, not averages: uncompressed-gradient rank uses attention q/k/v/o at layers 6, 13, 20 plus MLP gate/up/down at layer 13; grad_h rank uses backward activation gradients dL/dh at pipeline boundaries 6, 13, 20. Those boundaries are realistic PP cuts from 2-way and 4-way splits of the 28-layer decoder.
1Gradient-direction staleness - easy vs hard
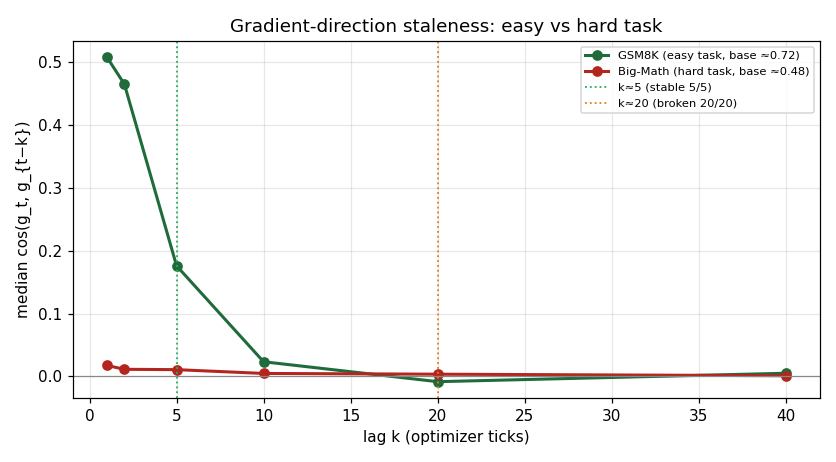
Median gradient cosine cos(g_t,g_{t−k}) vs lag, GSM8K vs Big-Math (separate series).
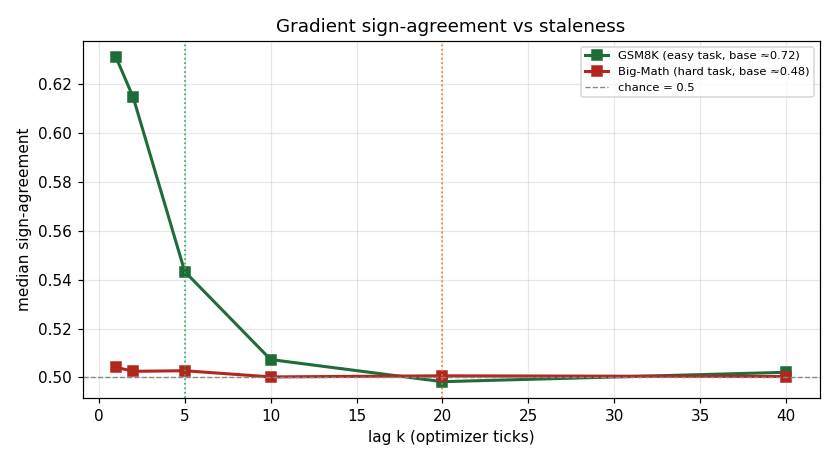
Median gradient sign-agreement vs lag (chance = 0.5).
The uncompressed normal run measures the parameter-point gap (gap 1): how much the gradient changes because the model weights moved from an old point θ_{t-k} to the current point θ_t. This curvature term (gap 1) is the part that ordinary SFT (supervised fine-tuning on a fixed dataset) also has — and SFT tolerates it. (We ran no SFT here; SFT is only a reference point.) What makes on-policy GRPO fail is a second term that SFT lacks — the distribution gap (gap 2, §6). It is called curvature-bounded because, on a smooth loss surface, the error can be bounded by how curved the loss is and how far the weights moved. On
the EASY task it decays from cos 0.507 (k=1) to 0.176 (k≈5) to ≈0 by k≈10; on the
HARD task it is already ≈0.018 at k=1; the uncompressed gradient direction carries almost no
reusable information across even a single tick. The gradient-anchor staleness budget is task-dependent and
near-zero on the hard task.
2Nature of learning - gradient effective rank over training
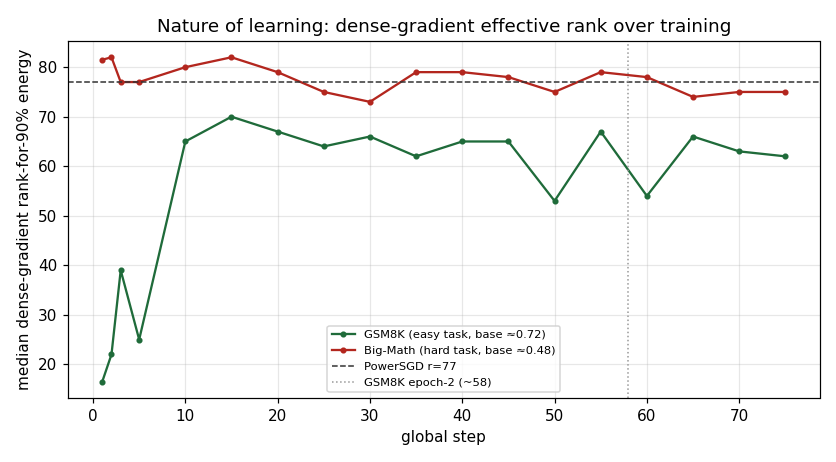
Median uncompressed-gradient rank-for-90%-energy over training (per dataset), vs r=77.
Median uncompressed-gradient rank-for-90%: 50 (GSM8K) vs 78 (Big-Math, right at the low-rank compression budget r=77). On GSM8K the naive ≤58-vs->58 epoch split (48→61) is a warmup-binning artifact; post-warmup the rank is stationary (65 vs 61 across step 58). Big-Math crosses no epoch boundary in 75 steps.
3Boundary activation & the forward/backward asymmetry
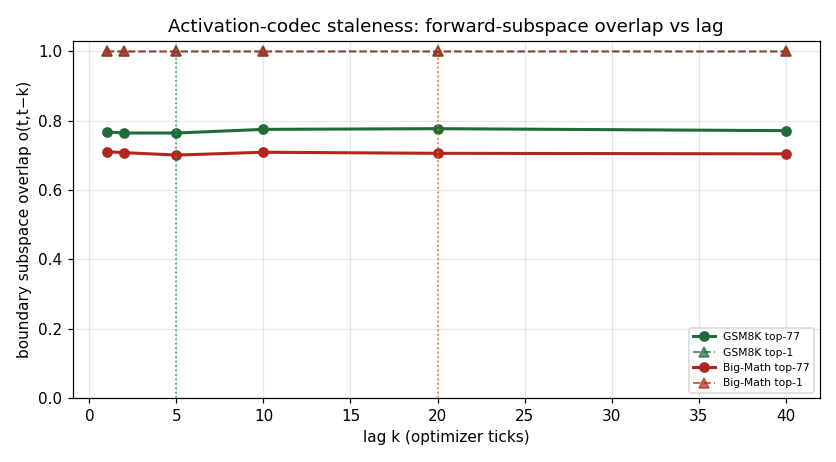
Boundary forward-subspace overlap o(t,t−k) vs lag (top-77 solid, top-1 dashed), per dataset.
Rank-for-90% of uncompressed grad, boundary h, and boundary grad_h vs low-rank compression budget r=77 (easy vs hard).
The forward activation h is rank-≈1 on BOTH tasks (top-1 energy
0.991 / 0.986)
- a massive-activation direction dominates, so rank-r forward compression is the right primitive and r=77 is
hugely over-provisioned, task-independently. The subspace overlap is flat across lag (Q is stale-tolerant).
But the BACKWARD grad_h is rank 105 (GSM8K) /
180 (Big-Math) - above r and growing with task hardness: the
backward link is NOT as compressible as the forward, and the gap widens on the hard task.
4Hypotheses, per task
| hypothesis | GSM8K (easy) | Big-Math (hard) |
|---|---|---|
| H1 - gradient-space staleness budget crossed by ~20-tick lag | SUPPORTED cos 0.176→-0.008; sign 0.54→0.50 |
SUPPORTED (budget ≈ 0) cos 0.011→0.004; sign 0.50→0.50 |
| H2 - drift is GRPO-coupled (distribution gap), not pure parameter-point gap | SUPPORTED | SUPPORTED |
| H3 - boundary activation low-rank with a Q-staleness budget | SUPPORTED (staleness-insensitive) h rank≈1.0; o(t,t−20)=0.777 |
SUPPORTED (staleness-insensitive) h rank≈1.0; o(t,t−20)=0.706 |
H1/H2/H3 are re-resolved from each arm's own findings with the identical resolver used in the per-arm
reports - so these verdicts match exp38-dense-drift-gsm8k.html / -big-math.html exactly.
5Headline numbers, side by side
| metric | GSM8K | Big-Math | note |
|---|---|---|---|
| Gradient cos at k=1 (lag-1 tick) | 0.507 | 0.018 | the most-correlated case - the hard task is decorrelated even here |
| Gradient cos at k≈5 (stable 5/5 anchor) | 0.176 | 0.011 | |
| Gradient cos at k≈20 (broken 20/20 anchor) | -0.008 | 0.004 | |
| Gradient sign-agreement at k≈5 | 0.543 | 0.503 | chance = 0.5 |
| Uncompressed-gradient rank-for-90% (median) | 50.0 | 78.0 | vs compression budget r=77 |
| Boundary h rank-for-90% (median) | 1.0 | 1.0 | ≈ rank-1 on BOTH (massive activation) |
| Boundary h top-1 energy share | 0.991 | 0.986 | fraction of energy in 1 direction |
| Boundary grad_h rank-for-90% (median) | 105.0 | 180.0 | backward link, vs r=77 |
| Top-77 subspace overlap o(t,t−20) | 0.777 | 0.706 | Q-staleness (flat = stale-tolerant) |
| H2 weight half-drift lag (global steps) | 7.9 | 7.9 | behaviour signals beat this in both arms |
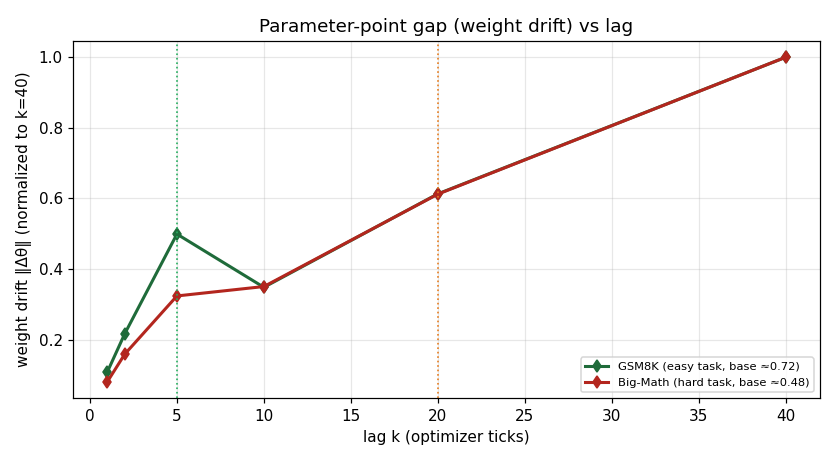
Weight drift (parameter-point gap) vs lag, normalized per arm.
6Theory - why this matters for the next method
The central task-dependence finding
The uncompressed-run gradient carries a task-dependent temporal-correlation budget, and that budget is the single sharpest difference between the easy and hard tasks. On GSM8K the consecutive-tick gradient direction is meaningfully aligned - cos(g_t, g_{t-1}) = 0.507, cos(g_t, g_{t-5}) = 0.176 - so there is a short but real window over which a lagged gradient still points roughly the right way. On Big-Math that window is essentially absent: cos(g_t, g_{t-1}) = 0.0175, already at noise floor at lag 1, with sign-agreement 0.503 against a chance baseline of 0.5. The hard task's uncompressed gradient is decorrelated tick-to-tick, where the easy task's is not.
The differences extend to the gradient's shape, all pointing the same way - the hard task is harder to compress and harder to lag:
- Gradient staleness budget: GSM8K has a usable short window (cos
0.51 → 0.18overk = 1 → 5, then≈0byk = 10); Big-Math has effectively zero budget (cos≈0atk = 1). - Uncompressed-gradient rank-for-90%-energy:
50(GSM8K) vs78(Big-Math) - the hard task's gradient is higher-rank, sitting right at the locked PowerSGD low-rank compression budgetr = 77. - Boundary backward-traffic rank (grad_h):
105(GSM8K) vs180(Big-Math) - backward traffic is markedly higher-rank on the hard task and already exceedsr = 77on both.
Against this, one structure is invariant across both tasks: the boundary forward activation h is rank-1 by a massive-activation outlier (rank-for-90% = 1; top-1 singular direction holds 99.1% of energy on GSM8K, 98.6% on Big-Math; stable rank ≈1.01 on both). The forward link looks the same whether the task is easy or hard.
Headline: the next method's staleness and low-rank compression budget must be set per task - the gradient's temporal-correlation window collapses from a workable cos≈0.18@k5 on GSM8K to cos≈0@k1 on Big-Math, and its rank climbs from 50 to 78; only the rank-1 forward activation is task-independent and safe to budget globally.
Why two-circuit works for SFT (supervised fine-tuning) but fails for on-policy RL: sharpened by these numbers
The two-circuit design supplies a K-step-stale uncompressed gradient from a slow anchor. Its viability rests on two gaps. Gap 1 is the parameter-point gap: θ_t has moved from θ_{t-K}, so the lagged gradient is evaluated at old weights. This also exists in SFT (supervised fine-tuning on a fixed dataset). We call it curvature-bounded because smoothness and curvature of the loss can bound how wrong the old gradient direction is when the weights move only a little. Gap 2 is the distribution gap, which is RL-specific: the rollout distribution moves with the policy, so a stale on-policy gradient is a valid policy-gradient estimate for a policy that no longer exists, with no importance-sampling correction. This creates a low-variance, high-bias, persistent, cross-rank-identical force. In SFT the objective is a fixed expectation over a frozen dataset, so a lagged gradient is just a lagged estimate of the same objective: it telescopes and is error-feedback-recoverable. In GRPO it is the gradient of an old policy that the current model no longer follows.
This uncompressed normal run measures gap 1 only: both g_t and g_{t-k} are computed on-policy at their own ticks, so cos(g_t, g_{t-k}) isolates how fast the gradient direction itself decorrelates with lag. The verdict is that gap 1 alone is already fatal at the broken cadence. On GSM8K the cosine reaches ≈0 by k ≈ 10 (0.023) and is at chance by k = 20 (-0.008, sign-agreement 0.498); on Big-Math it is at ≈0 at k = 1. A stale anchor is therefore doomed before gap 2 is even added. Gap 2 is present, because H2 shows 7/10 (GSM8K) and 9/10 (Big-Math) rollout/logprob/response signals reach half their drift no later than the weights do (weight half-drift lag ≈7.9 global steps), i.e. behaviour drifts comparably-or-faster than the weights that the cosine tracks.
This is consistent with EXP-37's empirical boundary. At cadence/delay 5/5 (k ≈ 5), GSM8K's gradient cosine is weak but positive (0.176): a small, frequent dose of a still-slightly-aligned signal survived. At 20/20 (k ≈ 20) the cosine is at chance (≈0): the broken anchor was injecting a near-orthogonal, biased force every refresh, which ignited. The uncompressed-run decorrelation curve and the SFT/GRPO asymmetry together explain why 5/5 was the edge of stability and 20/20 was past it.
The activation-compression verdict (H3) and the forward/backward asymmetry
The forward activation evidence is unusually clean and points to over-provisioned forward low-rank compression. The boundary h is rank-1 on both tasks (rank-for-90% = 1; top-1 energy 99.1% / 98.6%; stable rank ≈1.01), so low-rank activation compression is exactly the right primitive - and a rank-77 basis is hugely over-provisioned for the forward link, where one or a handful of directions would suffice. Crucially, the compression basis does not need to chase drift: the top-r=77 subspace overlap o(t,t-k) is flat across all lags (≈0.77 on GSM8K for k = 1..40; top-1 overlap ≈1.0; Big-Math o(t,t-20) = 0.706). Compression-basis staleness is not the limiter on the forward link - a frozen or slowly-updated basis Q is stale-tolerant by construction here.
The backward link tells the opposite story and is the real warning. The boundary grad_h has rank-for-90% = 105 (GSM8K) and 180 (Big-Math) - both above r = 77, and rising with task hardness. The backward traffic is not as compressible as the forward traffic, and its rank grows precisely where we most want savings (the hard task). Do not set symmetric forward/backward compression budgets: a single shared rank that comfortably over-covers the rank-1 forward activation will under-cover the rank-105–180 backward gradient and silently discard signal - most severely on Big-Math.
The σ(M) ceiling and what it forbids/permits here
Let M = σ(g(θ_t), g(θ_{t-K})) - the information generated by the current and stale uncompressed-gradient means. Any deterministic route Φ(G_compressed, M) is σ(M)-measurable: it can only form a better or worse combination of those two means, so it cannot beat the uncompressed baseline. EXP-38 makes the cap concrete. The stale mean g(θ_{t-K}) is near-orthogonal to g(θ_t) at the broken cadence (cos ≈0 at k = 20 on GSM8K, at k = 1 on Big-Math), so reweighting, accumulating, momentum-averaging, or error-feedback over a stale uncompressed gradient is capped at parity at best and actively harmful when the stale term is biased - doubly so on the hard task, where there is no usable correlation to reweight even at lag 1.
This forbids the entire family of gradient-anchor-as-optimizer-signal routes: feeding a stale (compressed) full gradient into the step is dead per the H1 cosine collapse, and dead with no remaining margin on Big-Math. To surpass - or even safely match the uncompressed baseline, a method must inject information outside σ(M). EXP-38's evidence favours the escape categories that do not live in the stale-gradient span:
- Activation-space low-rank compression with a slow/frozen basis
Qon the forward link (rank-1h, lag-flat overlap) paired with a higher-rank backward link (grad_h rank105–180). This compresses the communication without ever treating a stale gradient as the optimizer signal - it stays orthogonal to theσ(M)trap. - Cross-rank 2nd-moment (disagreement-as-objective): variance across the swarm's concurrent same-
θgradients is information the uncompressed baseline's Adam (its diagonal) does not contain. - Curvature / 2nd-order information about
θ_t, again outside the two gradient means.
Concrete next-method recommendation
Compress in activation space, not gradient space - and split the budget. The forward link is the prize: h is rank-1 with a lag-flat top-subspace, so low-rank activation compression with a slow or frozen basis Q captures nearly all forward energy at a tiny budget and is intrinsically staleness-tolerant (subspace overlap flat at ≈0.77 across k = 1..40). The backward link must get a separate, higher rank - at least ~105 for GSM8K-class tasks and ~180 for Big-Math-class tasks - because grad_h rank exceeds r = 77 on both and grows with hardness. Symmetric budgets will starve the backward path.
Re-cast the anchor as a slow compression-basis Q calibrator, not a gradient provider. The two-circuit anchor should maintain and broadcast the (slowly-varying, cross-rank-identical, staleness-tolerant) activation-compression basis - exactly the role the lag-flat overlap supports - rather than supply a stale uncompressed gradient to the optimizer. The gradient-anchor role is falsified here (cos collapse, H1) and offers no margin on the hard task; the compression-basis calibrator role is the natural, σ(M)-escaping use of a slow node.
Set the budget per task. The easy-vs-hard divergence is too large to paper over with one constant: gradient rank 50 vs 78, backward rank 105 vs 180, and a usable gradient-staleness window (cos ≈0.18@k5) on GSM8K that simply does not exist on Big-Math (cos ≈0@k1). Any allowed staleness K and any backward rank must be calibrated to the task; a budget tuned on GSM8K will under-rank and over-lag on Big-Math. The only quantity safe to fix globally is the forward-compression rank, because the rank-1 massive-activation structure of h is task-independent.
Priority order: (1) activation-space forward compression with frozen/slow Q; (2) independent higher-rank backward compression, rank set per task; (3) anchor demoted to Q-calibrator; (4) if surpassing the uncompressed baseline is sought, layer a cross-rank 2nd-moment or curvature term - never a stale-gradient reuse term.
Caveats
- Single trajectory, short horizon.
n = 1per task over75global steps (150optimizer ticks). All numbers are one realisation; treat magnitudes as indicative, not population estimates. - Capture-schedule confound on small lags. The
k ≤ 5gradient cosines are sampled predominantly in early training, so the short GSM8K staleness window is partly an early-training measurement and may not hold uniformly across the run. - Knees are consistencies, not proofs. Every alignment to EXP-37 - GSM8K cos
0.176@k5with the stable5/5anchor, cos≈0@k20with the broken20/20anchor - is framed as consistent / inconsistent with the5/5-stable,20/20-broken boundary, not as a causal demonstration. This uncompressed normal run measures gap 1 only; gap 2's contribution is inferred from H2's behaviour-drift signals, not directly observed under a stale anchor. - Epoch boundary. GSM8K crosses into epoch 2 at step
58with no clean jump in gradient rank (flat across the boundary); Big-Math crosses no epoch boundary (train cap20000⇒~156steps/epoch). The flat-across-epoch GSM8K rank is reassuring but is, again, a single run.
n=1 per task, 75 steps each - within-run measurements on the uncompressed run, not cross-seed statistics.
Small-lag (k≤5) gradient cosines are sampled only in early training (capture-schedule confound). Knees are framed
as "consistent / inconsistent with" the EXP-37 5/5-stable, 20/20-broken boundary. Datasets are never merged: every
curve is derived from its own arm's *_findings.json. Generated by research/scripts/exp38_compare.py.