Why the comm-eff EMA merger is stable at anchor latency K=5 but collapses at K=20
One method, one knob. The EMA merger signed_ema (α=0.25, βanc=0.50) tracks the dense ceiling at K=5 and collapses below the no-merger floor at K=20. The verdict, the evidence, the next steps.
1Executive summary
The same EMA merger that works at anchor latency K=5 (val@50 0.7362, ~0.03 below the dense ceiling) collapses when the latency is raised to K=20: val@50 lands at 0.6482 — 0.088 below the K=5 baseline — then a back-half length spiral drives accuracy to 0.4435 by step 100, below the 0.6300 no-merger floor, so the correction is not merely inert but actively destructive. The latency genuinely ran (anchor_backwards=10); this is a real result, not a config artifact.
The cause is anchor-gradient staleness, which K controls. The stale correction becomes a coherent, reward-flat tangential push (a “length ratchet”) that nothing brakes on a no-KL / no-entropy objective, and its gain scales with K. Within the two-knob circuit the verdict is that gradient staleness (delay_K) is PRIMARY (~70–80% of the val drop) and Q-refresh cadence is SECONDARY (~20–35%); both analysts agree ignition is lag-driven but differ on whether magnitude (delay_K) or hold-length (cadence) sets its timing. The split is theory-estimated; a decoupling run isolates it (§6).
K=5 — does the EMA merger work?
YES — stable, val@50 0.7362 (~0.03 below dense)
K=20 — same merger, 4× the latency?
COLLAPSES — val@100 0.4435, below the 0.6300 floor
2Setup: K and the anchor / EMA circuit
The circuit. At the pipeline boundary the dense gradient is replaced by a compressed fast gradient G_comp (PowerSGD-projected, r=77), periodically corrected by an anchor: a no-hook clone that runs forward/backward from a stale weight snapshot θt−K on the data those weights generated (paired replay) and produces a full-coverage dense gradient M. The merger signed_ema folds M in each tick as G_corr = α·G_comp + (1−α)·|G_comp|·sign(M) — it keeps the fast gradient's magnitude but adopts the anchor's sign per coordinate.
What K is. K is the anchor latency, counted in optimizer ticks, not global steps. On the locked surface (train_batch=128, ppo_mini=64) there are 2 ticks per global step. K bundles two sub-knobs raised together through one firing gate:
delay_K— how stale M is (the gradient atθt−K).cadence— how often the anchor fires; each fire refreshes M, re-fits the PowerSGD basis Q, and re-bases the held correction.
So K=5 = 2.5 global steps of staleness, Q refreshed every 2.5 steps; K=20 = 10 global steps stale, Q refreshed every 10 steps — 4× the lag and 4× the refresh interval. EXP-37 changed only these two knobs (5→20) relative to the good K=5 baseline (EXP-36B) and extended the horizon to 100 steps to probe the back half. Merger, codec, and surface are otherwise identical.
3The evidence
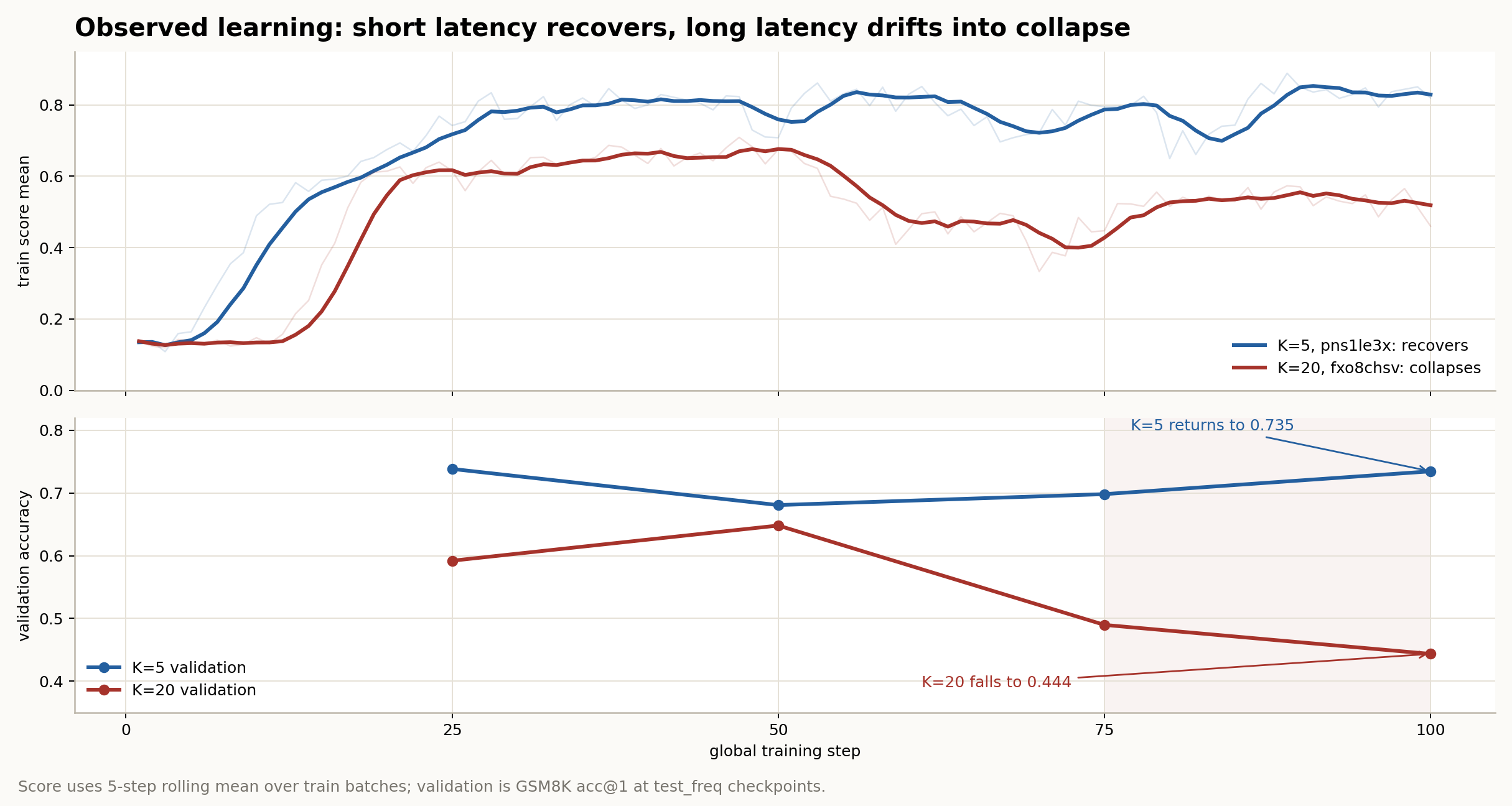
signed_ema merger holds near the dense ceiling at K=5 (stops at step 50, pre-spiral) but collapses below the no-merger floor at K=20, falling from 0.648 at step 50 to 0.444 by step 100 as the length spiral ignites around step 93. All points are single runs (n=1); rollout noise ≈±0.024 (shaded band).| Run | Config | val@25 | val@50 | val@75 | val@100 |
|---|---|---|---|---|---|
| Dense control (EXP-36C) ceiling | no comm-eff | 0.7627 | 0.7657 | — | — |
| EXP-36B K=5 | signed_ema, K=5 | 0.7263 | 0.7362 | — | — |
| EXP-37 K=20 | signed_ema, K=20 | 0.5921 | 0.6482 | 0.4898 | 0.4435 |
val@50 degradation = 0.0880, above the 0.05 “remains near base” gate → K=20 fails the headline bar. Terminal val 0.4435 < 0.6300 no-merger floor: the EMA correction at K=20 is worse than dropping the anchor entirely.
The collapse mechanism
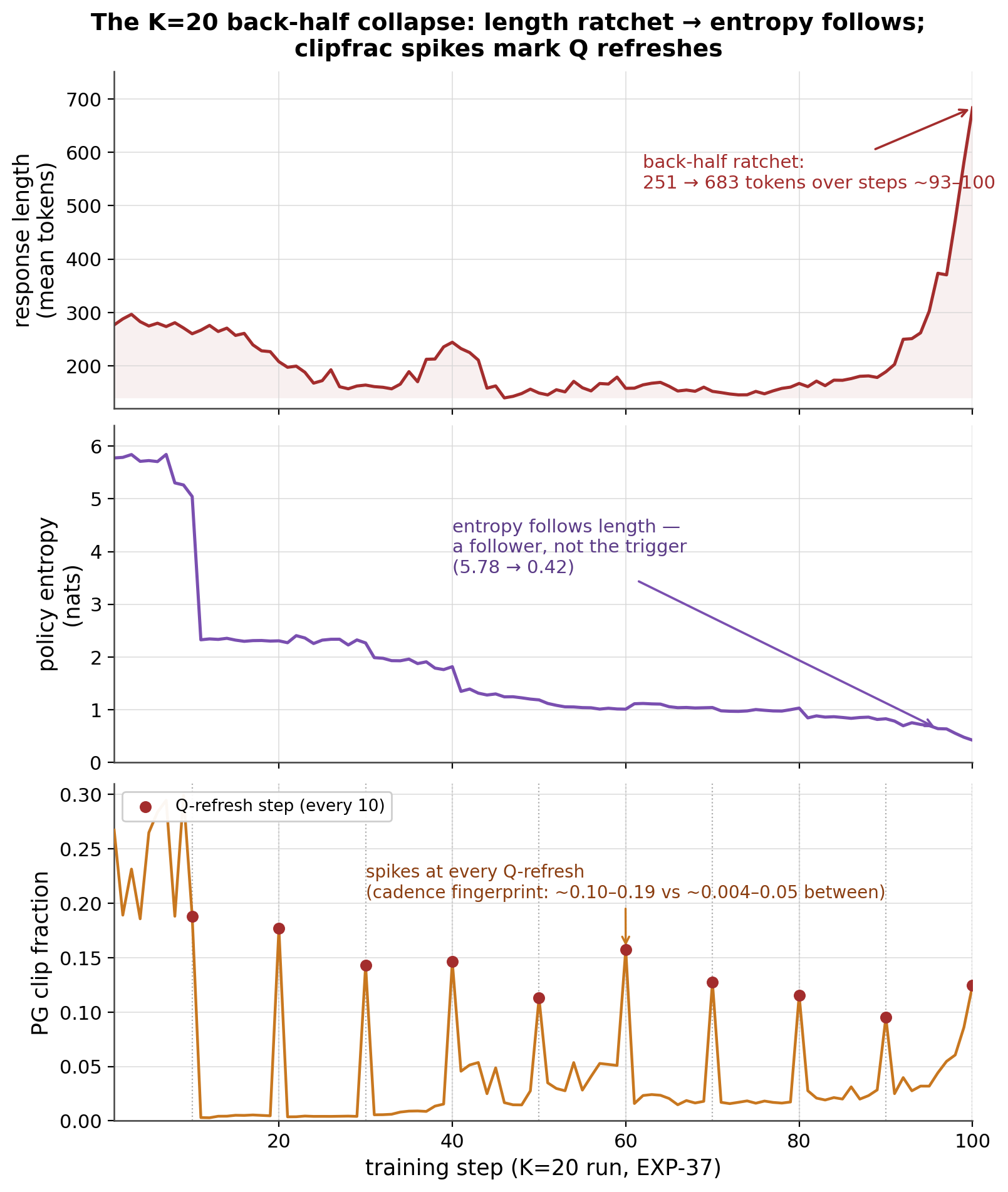
The ordering is the load-bearing fact and matches the locked record: length runs away first, entropy follows. A persistent push drifts the policy along the reward-flat “correct-but-longer” ridge (§4b); with no KL/entropy brake it self-sustains. The periodic clipfrac spikes are the one purely-cadence signature (§5).
4Theory: why K=5 is sub-critical and K=20 is super-critical
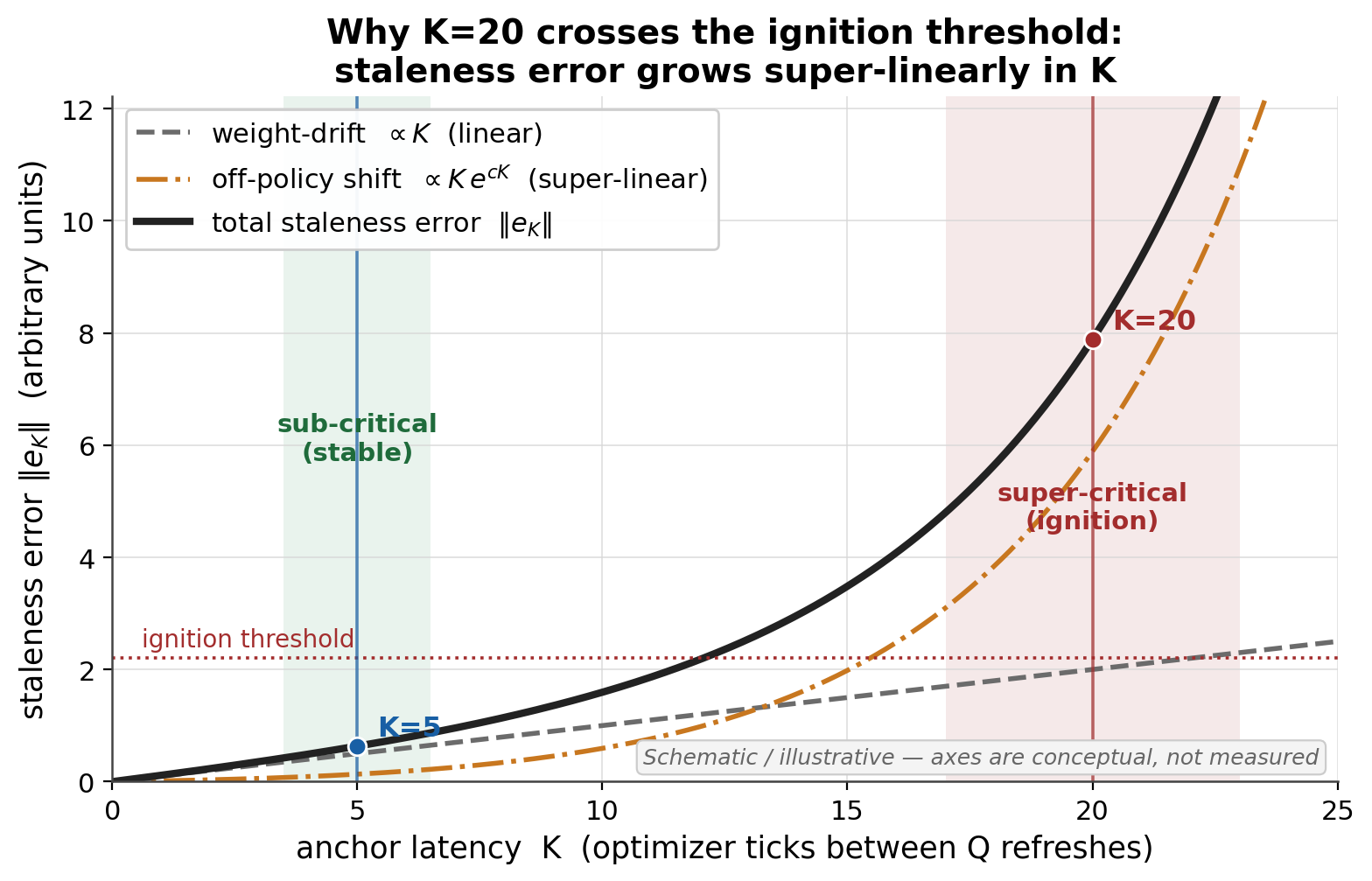
Four load-bearing points.
(a) The staleness error grows linear-plus-super-linear in K
Write eK = g(θt) − g(θt−K). It splits into a weight-drift term, linear in K (bounded by LH·K·η·‖u‖ — K=20 has 4× the drift of K=5), plus an off-policy distribution-shift term that grows super-linearly: M was computed on data sampled from a different policy πθt−K, and under GRPO the importance-weight variance grows ~exp(DKL) while the clip converts that variance into a bias growing with divergence. Because Adam + grad-clip make the update direction load-bearing, what matters is the angular error: as ‖eK‖ approaches ‖g(θt)‖, sign(M) points uphill on more coordinates — correlated wrong-sign flips in the merger.
(b) The corruption becomes a reward-flat length ratchet; gain ∝ K
On coordinates where sign(M) ≠ sign(G_comp) the merger injects a partially sign-reversed force: its net projection onto the reward gradient is small or slightly negative, and its large component lies along reward-flat (length-manifold) directions that absorb it. The result is a persistent push along the reward-flat manifold. “Correct-but-longer” is exactly such a ridge, and with no KL/entropy term nothing brakes it. Token-mean loss normalization makes each token's gradient weaker as sequences grow (dF/dℓ > 0) — the signature of positive feedback. Staleness sets the loop gain: larger K ⇒ larger per-step tangential dose, moving the system from sub-critical (K=5: ratchet present but censored at 50 steps) to super-critical (K=20: ignites within 100).
(c) Late onset is an integral threshold-crossing
The spiral is the integral of a small biased force, so it accumulates before it self-sustains. Two effects back-load the damage into the second epoch (boundary at step 50): cumulative drift ‖θt−θ0‖ is largest then (maximizing the off-policy term), and the held correction integrates ever-more mis-aimed fires across the cadence window. EXP-37's degradation building through the back half and ignition near step 93 is exactly this integral-threshold (ratchet) signature.
(d) The σ(M) ceiling: staleness can only degrade — no K helps
Any deterministic correction Φ(G_comp, M) is measurable w.r.t. σ(M)=σ(g(θt), g(θt−K)) and is therefore capped at dense. A K-stale M is a strictly noisier estimate of g(θt) under our drift + off-policy model, so the recoverable dense information is expected to be (weakly) decreasing in K. Staleness adds no curvature, exploration, or cross-rank signal — it only corrupts the dense reconstruction. There is no value of K that helps. Since the async north-star (one slow anchor, fast swarm, lag always present) forces K large and variable, the goal is robustness to staleness, never exploitation of it.
5The two-hypothesis verdict
K bundles two sub-knobs; the question is which drives the collapse. Both analyses — one owning delay_K, one owning the codec/cadence — converge on the same weighting.
H1 — M too stale? (delay_K)
YES · PRIMARY
~70–80% of the val drop. The off-policy term is a pure function of K and the ratchet gain scales with ‖eK‖ ∝ K. Both analysts agree ignition is lag-driven; what stays unresolved is whether delay_K magnitude or cadence hold-length sets its timing — the decoupling run settles it.
H2 — Q refreshed too rarely? (cadence)
CONTRIBUTES · SECONDARY
~20–35%. A frozen Q injects a bounded, self-healing error: warm-start pulls Q one power step toward the current subspace each fire, and activation geometry is slow-varying. Cadence is the clock, not the engine.
Consensus midpoint of the two analysts' independent estimates.
The structural confound. EXP-37 alone cannot cleanly separate the two: cadence and delay_K are gated by the same per-tick counter through the same anchor_should_fire(step, cadence) call — Q-update, M-refresh, and broadcast all happen in one fire block. Raising K to 20 makes “Q frozen 4× longer” and “M 4× staler” inseparable in this run. Hence the attribution above is theory-grounded, not measured — and the decoupling run (§6) is what converts it.
The one isolable cadence signature. A pg_clipfrac spike at every Q-refresh step (10, 20, …, 100): ~0.10–0.19 at refreshes vs a ~0.004–0.06 floor between, once the merger engages (after the ~10-step warmup, where it sits ~0.19–0.30) and rising toward the back half (Figure 2, bottom panel). Each fire jumps Q discontinuously, mismatching the importance ratio for one step; the spikes are larger precisely because the jumps are rarer at cadence 20. This is the cleanest already-available pure-cadence readout. The scalar Q telemetry confirms this: Q remains well-conditioned and low-error after the first update, so cadence contributes as a refresh shock/hold-length effect, not as a catastrophic PowerSGD compression failure.
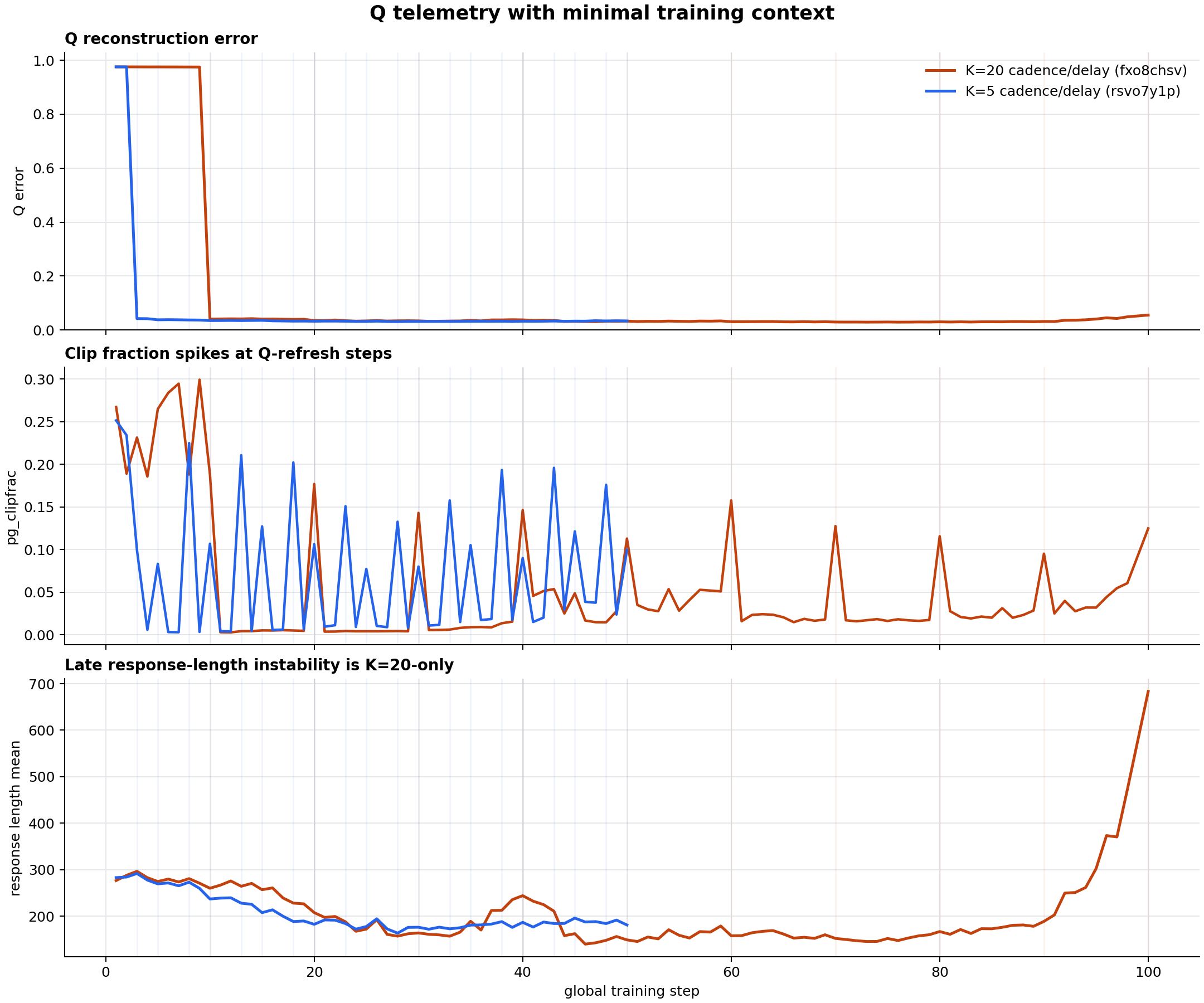
6Ranked next steps
Ranked by expected payoff per unit cost, all respecting the async constraint (the anchor must stay a lagging reference; corrections cross-rank-identical and graceful as the anchor ages).
Cells: {delay_K, cadence} ∈ {5, 20} · surface: accel, 100 steps, same signed_ema (α=0.25, β=0.50)
The single experiment that settles the confound. Cell B {delay_K=20, cadence=5} is most informative: a short held-correction window but large per-correction magnitude. If it reproduces ignition, the gain is unambiguously the delay_K magnitude, not Q-refresh rarity — converting the ~75/25 attribution from theory to data.
| Cell | delay_K | cadence | Isolates | Predicted |
|---|---|---|---|---|
| A (= EXP-36B) | 5 | 5 | control | stable, val@50 ≈ 0.736 |
| B (delay-only) most informative | 20 | 5 | delay_K at fixed Q-refresh | ignites + val drop ≈ EXP-37 |
| C (cadence-only) | 5 | 20 | stale Q at fixed staleness | mostly stable (≈0.71–0.73) |
| D (= EXP-37) | 20 | 20 | both (have it) | 0.5921 / 0.6482 / collapse |
B≈D confirms delay_K; C≈D would flip the verdict to cadence; a half-and-half split means both axes need fixing. Cell B is only expressible once step #3's q_cadence decoupling lands.
Cost: 2 extra cells × 100 steps, one box, back-to-back. If budget allows one, run Cell B.
Knob: delta_momentum_age_decay (already in code) · value: μ ≈ 0.85–0.90
Scale the held correction by μage as it ages. At K=20, 0.8820 ≈ 0.08, so the correction is strong right after a fresh fire and near-zero before the next — directly capping the integrated tangential dose (the ratchet gain in §4b) without touching K or the two-circuit structure. Cross-rank-identical and graceful-by-age, so async-admissible. Age-decay was mildly harmful as a freshness lever at K=5 (it discards good signal), but at K=20 the late-window correction is bad signal — a falsifiable sub-prediction that it helps where it hurt.
Cost: config-only. Test inside the decoupling run.
q_cadence)Knob: NEW q_cadence · value: q_cadence=5 (or per-tick) while delay_K=20
Refresh Q cheaply and often even while M stays stale. The Q update is just orth(V) on the fast-path activation sketch plus a small H×r broadcast — it needs no stale backward, so refreshing Q is nearly free relative to the anchor pass that produces M. This shrinks the per-refresh projector-jump shock and is what makes Cell B expressible. Engineering flag to systems: the replay ring keys fire-aware retention on cadence (anchor.py:426, _keep_residue = (−delay_K) % cadence); a split cadence requires the ring to key on the M-refresh cadence, not the Q one. This is the one real subtlety.
Cost: new knob (off the locked surface) + ring re-key. Q-refresh itself is nearly free.
beta_anc=0 + adaptive-λ ratio mode with a low capKnobs: beta_anc=0 · adaptive_lambda_mode="ratio", lambda_cap ≈ 0.5
Averaging old gradients (β>0) compounds staleness, and GRPO's clip tolerates far less of that than SFT. Keep beta_anc=0 and fight staleness with dose decay (#2), not smoothing. As a safety belt, gate the dose on measured staleness ct=‖δ‖/‖gm‖ (a large residual relative to the live gradient = a badly-aged anchor ⇒ drop the dose); a low lambda_cap ensures a staleness spike cannot spike the dose. Bounded, variable-staleness-safe, cross-rank-identical.
Cost: config-only. Complements #2; can share a cell.
Delay-compensation / extrapolation / lead. Predicting g(θt) from the stale gradient (Nesterov-style lead) is forbidden by the async target: the anchor is one slow node that can never lead the swarm. Admissible levers use it as a lagging reference only.
Chasing PowerSGD rank r. Reconstruction error is flat across r∈[77,102] — the codec is not coverage-starved, so raising r buys little and costs comm linearly. Do not lead with it.
7Caveats
- n=1 draws. Every val number is a single run; rollout nondeterminism is ~±0.024 (the dense draw band), so differences below that are within noise. The EXP-37 effects (0.088 drop at val@50, collapse to 0.4435) are far outside it; read the §6 cell predictions with the ±0.024 band in mind.
- The cadence/delay confound limits standalone attribution. The 70–80% / 20–35% split is theory-grounded, not measured (see §5); the §6 decoupling run converts it to measurement.
- Comm-cost accounting. The reported
bytes_ratio ≈ 0.0502counts only the fast-path Y + amortized Q; the full-dense M broadcast is a known-uncounted term and is not the total communication cost.
signed_ema (α=0.25, βanc=0.50). Mechanism claims are grounded in the comm-eff source (spectral_filter.py, transformer_impl.py, anchor.py, powersgd_activation.py) and the standing research memory. Prepared 2026-06-18.